
13
年
專
注
于
數
字
營
銷







隨著社交網絡與個人資料網站的興起,人們的個人信息已經成為了數字化時代的重要資產。然而,伴隨著這些網站的普及,用戶的個人隱私也受到了越來越多的威脅。為了解決這一問題,優化個人化推薦和用戶隱私保護已成為了當下亟需研究的課題之一。
一、社交網絡與個人資料網站用戶行為研究
為了了解社交網絡和個人資料網站用戶的行為習慣和興趣偏好,研究者們進行了大量的調查和研究。通過大數據分析和用戶調查,研究者們發現,社交網絡和個人資料網站的用戶主要有以下幾種行為模式:
1. 路人用戶:這類用戶通常是由于某些需求而進入社交網絡或個人資料網站的,例如需要找到某個人的聯系方式或者查找某一種產品的信息。他們通常只會訪問一次網站,并且不會填寫太多個人信息。
2. 群體用戶:這類用戶通常是從社交網絡或個人資料網站上發現了和自己有共同興趣的人,然后建立了連接。他們通常在社交網絡或個人資料網站上花費較多的時間,并且會分享一些個人信息和興趣愛好。
3. 潛在用戶:這類用戶通常是在社交網絡或個人資料網站上進行一些搜索,尋找和自己相關的信息。他們通常會花費一定的時間在社交網絡或個人資料網站上,并且會填寫一些基本的個人信息。
4. 忠實用戶:這類用戶通常是社交網絡和個人資料網站上的權威人士,他們通常在社交網絡或個人資料網站上擁有大量的關注者,并且會花費大量的時間在社交網絡或個人資料網站上。他們會分享大量的個人信息和興趣愛好,以便于自己的粉絲更好地了解自己。
二、優化個人化推薦
傳統的推薦算法通常會基于用戶所在的社交圈子、用戶的搜索歷史以及購買習慣等維度進行推薦。然而,這種推薦模式通常會帶來一些問題,例如用戶很容易遇到“信息孤島”、可能被推銷一些與個人興趣不相關的商品等。
為了解決這些問題,近年來,一些研究者嘗試使用更加個性化和精準的推薦算法。這些算法通常會基于用戶的個人資料、社交網絡中的關系網絡等維度進行推薦,從而達到更加精準的推薦效果。
例如,Facebook就采用了一種基于“矩陣分解”的推薦算法——Funky Factorization Machine(FFM)。這種算法可以對用戶的個人資料進行建模,并且通過學習用戶的社交網絡關系,對用戶進行更加精準的推薦。
三、用戶隱私保護
隨著社交網絡和個人資料網站的普及,用戶的個人信息已經成為了這些網站的重要資產。然而,用戶的個人隱私也受到了越來越多的威脅。為了避免個人信息被濫用,一些研究者提出了一些用戶隱私保護的方法。
1. 差分隱私:差分隱私是一種針對數據挖掘和機器學習場景下的隱私保護方法。總的來說,它通過對原始數據進行加噪處理,從而使得攻擊者無法通過對輸出結果的分析來推斷出原始數據的具體內容。
2. 匿名保護:匿名保護是一種通過對數據進行處理,使得數據中的個體無法被識別出來的隱私保護方法。例如,將城市出租車的行駛軌跡與某個地段的眾多居民的相同軌跡“迷霧化”,從而達到保護個人隱私的目的。
3. 隱私風險量化模型:隱私風險量化模型是一種通過對人們的行為進行模擬,并研究攻擊者可以采用的攻擊手段,從而識別和評估某個系統存在的隱私風險的方法。
結論
隨著社交網絡和個人資料網站的普及,優化個人化推薦和用戶隱私保護已經成為了當下亟需研究的課題之一。通過研究用戶的行為模式,探索更加個性化和精準的推薦算法,以及采用一些隱私保護方法,我們可以讓社交網絡和個人資料網站更好地滿足用戶的需求,保護用戶的個人隱私。




 生物醫藥網站建設
生物醫藥網站建設 IT科技網站建設
IT科技網站建設 網站集群網站建設
網站集群網站建設 教育培訓網站建設
教育培訓網站建設 智慧黨建網站建設
智慧黨建網站建設 上市公司網站建設
上市公司網站建設 小程序
小程序 APP開發
APP開發 系統開發
系統開發 確定建站目標
確定建站目標 深度調研策劃
深度調研策劃 建立視覺體系
建立視覺體系 創意視覺設計
創意視覺設計 前端交互開發
前端交互開發 短視頻推廣
短視頻推廣 短視頻競價
短視頻競價 短視頻矩陣
短視頻矩陣 抖音視頻營銷
抖音視頻營銷 媒體軟文營銷
媒體軟文營銷 網站SEO優化
網站SEO優化 系統私有定制
系統私有定制 數字運維監測
數字運維監測 集錦站群系統
集錦站群系統 集錦ERP系統
集錦ERP系統 集錦知識付費
集錦知識付費 數字內容系統
數字內容系統 集錦電商系統
集錦電商系統
 立即咨詢
立即咨詢
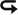




 立即咨詢
立即咨詢



 撥打電話獲取報價
撥打電話獲取報價







